Efficient Memory Management for Large Language Model Serving with PagedAttention
W Kwon 著 · 12 Sep 2023 · 被引用数: 5685・UC Berkeley, Stanford University, UC San Diego
GitHub
vllm
vllm-project • Updated Jun 6, 2026
Focus
Keyword
Batching(バッチ処理)
複数リクエストを同時実行してGPU利用率を上げるが、メモリ制約に強く縛られる。
KV cache(Key-Value cache)
自己回帰生成で過去トークンのK/Vを保持する巨大な状態。これがバッチサイズ上限を決める条件になりやすい
自己回帰型Transformer
- 入力(プロンプト)とこれまでに生成した出力トークンの以前のシーケンスに基づいて、一度に1つずつ単語(トークン)を生成
- 各リクエストに対して、この高コストなプロセスは、モデルが終端トークンを出力するまで繰り返す
プロンプトフェーズ(prompt phase)
- 入力:ユーザーが与えたプロンプト全体
- やること:最初の新規トークンの確率 を計算する。同時に、プロンプト中の各トークンの Key/Value(= KV cache) をまとめて作る。
- 計算特性:プロンプトトークンがすべて既知なので、位置方向にまとめて処理でき、行列積(matrix-matrix multiplication)で並列化しやすくGPUを効率よく活用できる
自己回帰生成フェーズ(autoregressive generation phase)
- 入力:各反復 で「直前までに確定した最新トークン」 と、そこまでの文脈
- やること:次トークンの確率 を計算して、1トークンずつ生成を進める。
- このとき 過去トークンのK/Vはキャッシュ済みなので、各反復で新たに作るのは基本的に新規トークン分の 。
- 計算特性:反復間にデータ依存があるため ステップ間の並列化ができない。計算はしばしば 行列ベクトル積(matrix-vector multiplication)中心になり、GPUの並列性を活かしにくい。結果として メモリ律速になりやすく、単一リクエストのレイテンシの大部分を占めやすい。
Internal fragmentation(内部断片化)
最大長に合わせて過剰確保した使われない部分が同一チャンク内に発生。
External fragmentation(外部断片化)
確保・解放の繰り返しで、空きはあるのに連続領域が取れない等の無駄が発生。
Reserved / pre-allocation(予約・事前確保)
将来トークン用に最大長分を確保して塞ぐため、他リクエストが入らない。
Memory sharing(メモリ共有の機会損失)
beam search や parallel sampling などで共有できるはずのKVを、既存方式では共有しにくい。
PagedAttention
OSのページングに着想し、KVを「ブロック(ページ)」として扱い、物理メモリ上で非連続でもattention計算できるようにする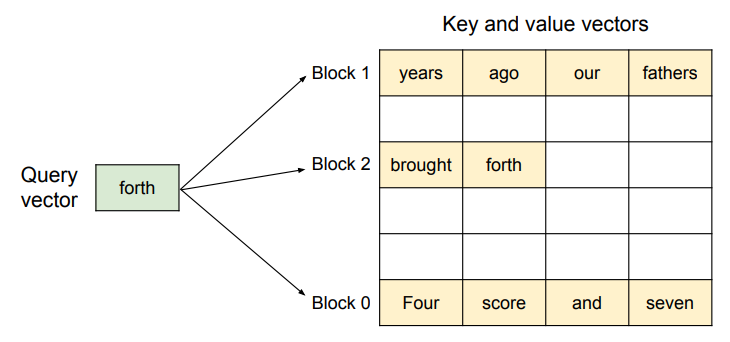
- アテンションのキーおよびバリューのベクトルが、メモリ上で非連続なブロックとして格納されている様子
- 論文では、実装ではKとVは別ブロック(block tableも別)に分離して設計している(p5 脚注参照)
- K 用に の物理ブロック列を辿って読んで取り出す
- V 用に の物理ブロック列を辿って読んで取り出す
- キーとバリューのベクトルは3つのブロックに分散しており、これら3つのブロックは物理メモリ上で連続していない。各時刻において、カーネルはクエリトークン(「」)のクエリベクトル と、あるブロック内のキーベクトル (例:ブロック0における「Four score and seven」のキーベクトル)を乗算してアテンションスコア を計算し、その後、 を同じブロック内のバリューベクトル と乗算して、最終的なアテンション出力 を得る
KV blocks(KVブロック) / Block size(ブロックサイズ)
固定サイズ単位にKV cacheを分割。小さく必要に応じて割り当てることで断片化を抑える。
- 1つのKVブロック内に複数トークンを格納する(ブロックサイズ > 1)ことで、PagedAttentionカーネルはより多くの位置にまたがるKVキャッシュを並列に処理でき、ハードウェア利用率の向上とレイテンシ低減につながる
- 一方で、ブロックサイズを大きくするとメモリ断片化も増える
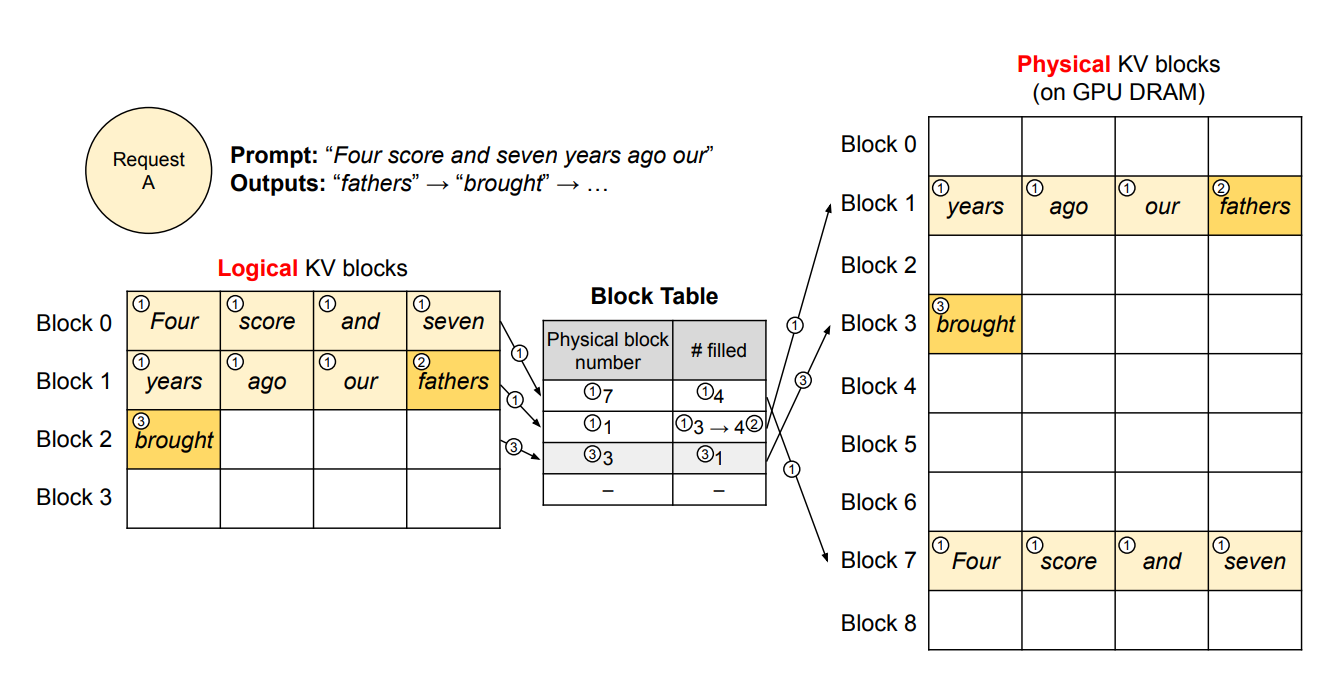
Logical vs physical blocks(論理ブロックと物理ブロックの分離)
リクエスト視点のKV cacheの並びと、GPU上のKV cacheの実体配置を分離して柔軟に管理する
- CUDAメモリアロケータにも汎用のメモリ管理において仮想アドレス→物理の変換はある
- KV cacheというアプリケーション固有の論理構造を扱ったところにvLLMの新規性がある
Block table(ブロックテーブル)
各リクエストの論理ブロックが、どの物理ブロックに対応するかの対応表。
vLLM
PagedAttentionの上に作ったサービングエンジン。従来システムと比べ、KV cacheの無駄をほぼゼロに近づけることで、スループットを改善した
KV cache manager(KVキャッシュマネージャ)
ページング方式でKVを確保・解放・共有する仕組み
- スケジューラからの指示でGPUワーカー側の物理KVキャッシュメモリを管理する
- GPUワーカー上では、ブロックエンジンがGPU DRAMの連続チャンクを確保し、それを物理KVブロックに分割する(スワップのためにCPU RAM上でも同様に行う)
- 各リクエストの論理KVブロックと物理KVブロックの対応(マッピング)であるブロックテーブルを保持
- 各ブロックテーブルエントリには、論理ブロックに対応する物理ブロックと、埋まっている位置数が記録される
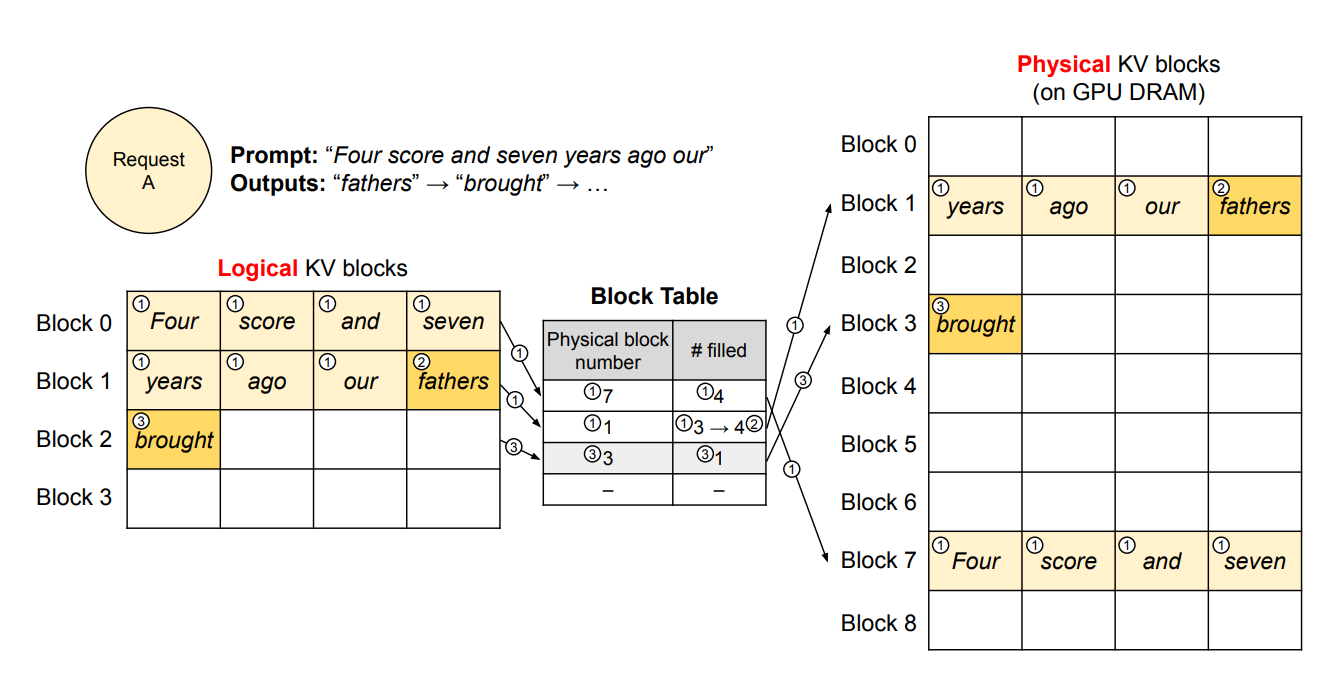
- vLLMはKV cache専用の仮想メモリ層を自前で作っている
- 論理アドレス空間(論理ブロック列)→ 非連続な物理ページ(物理ブロック)へマップ
並列サンプリング(Parallel sampling)
1つの入力プロンプトに対して、確率的サンプリングにより複数の出力系列(複数サンプル)を同時に生成するデコーディング形態。ユーザーは生成された複数候補から好みの出力を選ぶ
- 何が「並列」か
- 同一プロンプトを共有する複数シーケンス(例:sample A1, A2, …)を、同じリクエストの下で走らせる点が「並列」である
- ただし生成は自己回帰なので、各サンプル内ではトークン生成は逐次である
- メモリ(KV cache)上の重要ポイント
- プロンプト部分のKV cacheは全サンプルで共有できる(同じプロンプトなので同じKVになる)。
- 一方で 生成フェーズに入るとサンプルごとに出力トークンが分岐するため、KV cacheは共有できない(少なくとも「書き込みが起きる部分」は共有不可)。
- vLLM はこれを 物理ブロック共有 + 参照カウント + ブロック粒度のCopy-on-Writeで実現し、最後の論理ブロック(書き込みが発生し得る境界)だけCOWにする
Beam search
サンプル空間を完全に探索する計算量を抑えながら、LLMから最も確からしい出力シーケンスをデコードするために広く用いられている
- LLMでそれぞれの確率を計算したうえで、·|| 個(|| は語彙サイズ)の候補の中から上位件の確率の高いシーケンスを保持する
- 候補列(ビーム)間でプレフィックスを大量共有し得る
- → 共有パターンが動的に変わるため従来システムでは頻繁なメモリコピーでオーバーヘッドが大きくなる
Reference count(参照カウント)
1つの物理ブロックを複数論理ブロックが共有するための管理変数。
- 「ある物理KVブロックを、いま何本の論理ブロック(=何シーケンス)が参照しているか」を数えるカウンタ
Copy-on-write(COW)
共有中ブロックに“書き込み”が必要になったときだけ複製して分岐させる。OSのfork類似。
Shared prefix(共有プレフィックス)
共通のsystem prompt等のKV cache をサービス側で 物理ブロックとして事前にキャッシュしておき、ユーザごとのリクエストは自分の論理ブロックをそのキャッシュ済み 物理ブロックにマップして使い回す
- 最後のブロックの未使用部分は将来生成のために予約される
- それ以前のブロックは prefixのKVが完全に確定しており、immutable(以後一切書き換えられない)→ 読み取り専用
- つまり最後のブロックは、今後書き込み対象になりやすい(境界ブロック)
- 最後のブロックだけcopy-on-write(COW)対象にする
FCFS(First-come-first-serve)
公平性のため先着順を基本にする、という方針。
Preemption(プリエンプション)
メモリ不足時に一部シーケンスを中断・退避させて進行を制御する。
All-or-nothing eviction(全退避 or 無退避)
シーケンスのブロックはまとめてアクセスされる前提から、退避もまとめて行う設計。
Swapping(スワップ)
KVキャッシュをGPU→CPUメモリへブロックを退避して回復する方式。
- CPU RAMへスワップされるブロック数はGPU RAM内の物理ブロック総数を超えないため、CPU RAM上のスワップ領域はKVキャッシュ用に割り当てられたGPUメモリ量によって上限が定まる
Recomputation(再計算)
KVキャッシュは保存せず捨て、再開時に、prompt + 生成済みトークン列からKVキャッシュを再計算する方式。
Overview
WHAT(これは何?)
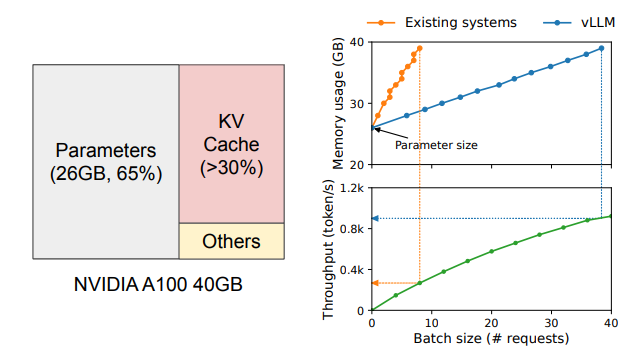
- 高スループットなLLMサービングでは、バッチ化で計算効率を上げても、各リクエストが保持する巨大なKVキャッシュがGPUメモリを圧迫してバッチサイズを制約しやすい。
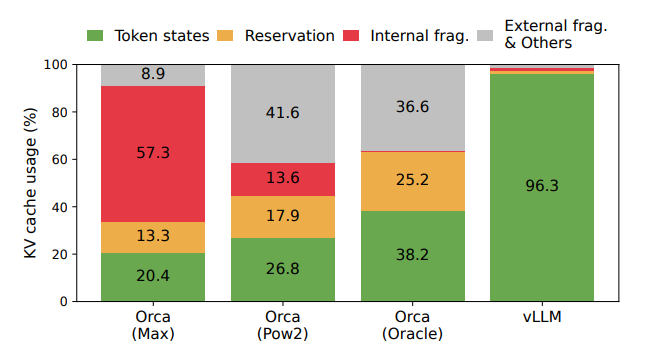
- KVキャッシュは生成に伴って動的に増減し、さらに連続メモリ前提(既存のDeepLearningのフレームワーク)の管理だと断片化や予約領域の無駄が増えて実効メモリが下がるため(2〜4割程度)、スループットはメモリ律速(Memory-bound)になりやすい。
- LLMの出力長は予測できないため、実際の入力長や最終的な出力長に関係なく、最大シーケンス長に基づいてメモリチャンクを静的に確保する
- → 断片化(内部断片化 internal fragmentation / 外部断片化 external fragmentation)を引き起こす
- 従来システムでは実効的に使えるメモリが20.4%まで低下し得る
最大長での事前確保

- デコーディング(特に parallel sampling / beam search)での共有のしづらさ
- 既存システムでは、各シーケンスのKVキャッシュが別々の連続領域に格納されているため、共有ができない
- どの程度共有できるかは、採用するデコーディングアルゴリズムに依存する
- そこで、OSの仮想メモリ(ページング)発想を持ち込み、PagedAttentionという注意機構+それを活かしたサービングエンジン vLLM を提案する。
WHY(提案手法の価値は?)
- KVキャッシュのメモリ浪費がほぼゼロに近づくように設計し、同じGPUメモリでより多くのリクエストを同時バッチできる。
- 例:NVIDIA A100からH100への移行ではFLOPSが2倍以上に増加する一方で、GPUメモリは最大80GBのままである → メモリがボトルネック
- 結果として、既存手法(例:FasterTransformerやOrca等)に対して、同等レイテンシ水準でスループットが2〜4倍(条件によってはさらに差が広がる)。
- 特に効果が出やすい条件は論文の主張だと以下:
- 長いシーケンス
- 大きいモデル
- 複雑なデコーディングアルゴリズム(beam search等)
- vLLM:異なるデコーディング設定を持つリクエストを同時に処理できる
- vLLMが、論理ブロックを物理ブロックへ変換する共通のマッピング層により、シーケンス間の複雑なメモリ共有を隠蔽するため
- メモリの持ち方が違っても同じバッチに載せられる
- vLLMは どのデコード方式でも最終的に物理ブロックIDの列に正規化してカーネルに渡す
- スケジューラはいま空いているブロックを割り当てられるシーケンスを集めて、同じイテレーションで流すことが可能
- さらに、parallel samplingやbeam searchのように「一部のプレフィックスは共有できるが、後半は分岐する」状況で、ブロック粒度の共有+Copy-on-Writeによりメモリ節約が可能になるのが強い。
WHERE(技術のキモはどこ?)
- LLMサービングのボトルネックとして、自己回帰生成フェーズのself-attention層に注目した
- プロンプト部分(共有プレフィックス含む)は共有できるが、自己回帰生成フェーズで「新しく増える部分」は共有できない
- → 可変で競合する状態を同じ実体として共有すると不正になる。しかし、Copy-on-Write 等で論理的に分離すれば共有できる
- vLLMの挑戦
- PagedAttention
- KV cacheを物理的に非連続に置いてもself-attentionを計算できるようにする
- KV cacheをKV blockに分け、カーネルが必要なブロックを個別にfetchしながらattentionを計算できるようになった
- 各ブロックは固定数のトークンに対応するキー・バリューベクトルを含み、この固定数をKVブロックサイズ()と呼ぶ
- KV Cache Manager
- 非連続な配置を利用し、KV cache全体をページング(固定サイズのKVブロック)として扱う仕組み
- 各リクエストの論理KVブロックと物理KVブロックを対応(マッピング)づける
- 論理KVブロックと物理KVブロックを分離することで、vLLMはKVキャッシュメモリを、全位置分を事前予約することなく動的に増やせるようになる
- メモリの浪費を解消し、バッチ可能数が増える
- デコーディング戦略
- 並列サンプリング(Parallel sampling)
- → 特に入力プロンプトが長い場合に、メモリ使用量を大幅に削減できる
- 各物理ブロックに参照カウントを導入し、1つの物理ブロックを複数シーケンスが共有できるようにする
- 生成が進むと書き込みが発生し、共有したままだと衝突する → copy-on-writeをブロック粒度で入れる
- サンプルA1が最後の論理ブロック(論理ブロック1)へ書き込みたい場合、
- vLLMは対応する物理ブロック(物理ブロック1)の参照カウントが1より大きいことを検知し、新たな物理ブロック(物理ブロック3)を割り当て、ブロックエンジンに物理ブロック1の内容をコピーさせ、参照カウントを1へ減らす
- サンプルA2が物理ブロック1へ書き込む時点では
- 参照カウントがすでに1まで下がっているため、A2は物理ブロック1へ直接、新しく生成したKVキャッシュを書き込める
- ビームサーチ(Beam search)
- 頻繁なメモリコピーのオーバーヘッドが削減される
- 1つの物理ブロックを複数のビーム候補が共有できるため、各物理ブロックに「何個の論理ブロックから参照されているか」を保持
- ビーム探索の途中で候補が脱落すると、その候補が参照していたブロックの参照カウントを減らし、参照カウントが0になった物理ブロックは解放できる
- 複数候補が共有しているブロックに対して、ある候補だけが新しいKVを書き込みたい場合、
- そのまま上書きすると他候補の履歴を壊してしまう
- → そこで、必要な分だけ新しい物理ブロックを割り当ててコピーし、その候補だけが書き込むようにする
- デコーディング手法の混在
- 異なるデコーディング設定を持つ複数リクエストを、同じバッチ内で処理できる
- 共通プロンプトを共有・再利用
- 長い system prompt や few-shot example など、複数リクエストで共通する prefix のKVキャッシュを事前に保存する
- 各リクエストでは、その共通 prefix のKVキャッシュを再計算せず、ユーザー固有の入力部分だけを計算する
- → prefill/proposal phase の計算量とメモリ使用量が減る
- スケジューリングとプリエンプション
- KV管理がうまくいっても、システム容量を上回ると物理ブロックが足りなくなる
- すべてのリクエストに対して先着順(FCFS: first-come-first-serve)のスケジューリング方針を採用
- vLLMがリクエストをプリエンプト(中断)する必要がある場合、先に到着したリクエストが先に処理され、後から到着したリクエストが優先的に中断される
- 対比方針:all-or-nothing
- 2つの復元方法のトレードオフ
- ブロックサイズが小さいときは再計算の方が効率的であり、ブロックサイズが大きいときはスワップの方が効率的
- ブロックサイズが16〜64の中程度の範囲では、両者は同程度のエンドツーエンド性能を示す
- 退避対象になったシーケンスの全KVブロックをGPUメモリからCPUメモリへコピーする
- 再開時も丸ごとGPUへ戻す
- 計算は節約できるが、CPU-GPU間転送が発生する
- ブロックサイズが小さいとCPUとGPUの間で多数の小さなデータ転送が発生し過大なオーバーヘッドを引き起こす
- 退避対象になったシーケンスの全KVブロックは全て解放し、
- 再開時はそのシーケンスのKVキャッシュを丸ごと作り直す
- (論文に言及はないが)CPUには軽量な生成済みトークン列だけ保存しておく
- 生成済みトークンは保持しているので、入力列としてまとめて与え、prefillステップ同様に全位置のKVキャッシュを計算するのみ
- 1トークンずつ自己回帰生成するステップは不要
- CPU-GPU転送は減るが、再計算コストが発生する
- モデル並列
- Megatron-LM 風のテンソルモデル並列戦略をサポート
- 分散メモリをグローバルに把握して指示するのが、集中型スケジューラ側のKVキャッシュマネージャ
- 実際にGPU上で確保・解放するのは各GPUワーカー側
- GPUワーカーはメモリ管理について同期する必要がない
- 各デコードイテレーションの冒頭で、ステップ入力とともにメモリ管理に必要な情報をすべて受け取れば済む
- 線形層とマルチヘッドアテンションを、テンソルの次元に沿ってGPU間に分割する
- 各GPUワーカーは同じ物理ブロックIDを持つ
- GPU間でall-reduceにより(スケジューラの調停なしに)中間結果を継続的に同期する
- アテンションヘッドのサブセットを各GPUプロセスが担当する
- GPUワーカーが実際に保持するKVキャッシュは、担当するアテンションヘッドに対応する一部分のみ
- アテンション層では、GPUワーカーは制御メッセージ内のブロックテーブルに従ってKVキャッシュを読み出す
vLLMでは、複数出力サンプル間でプロンプトのKVキャッシュが占める空間の大部分を共有できる
参照カウント(reference count)
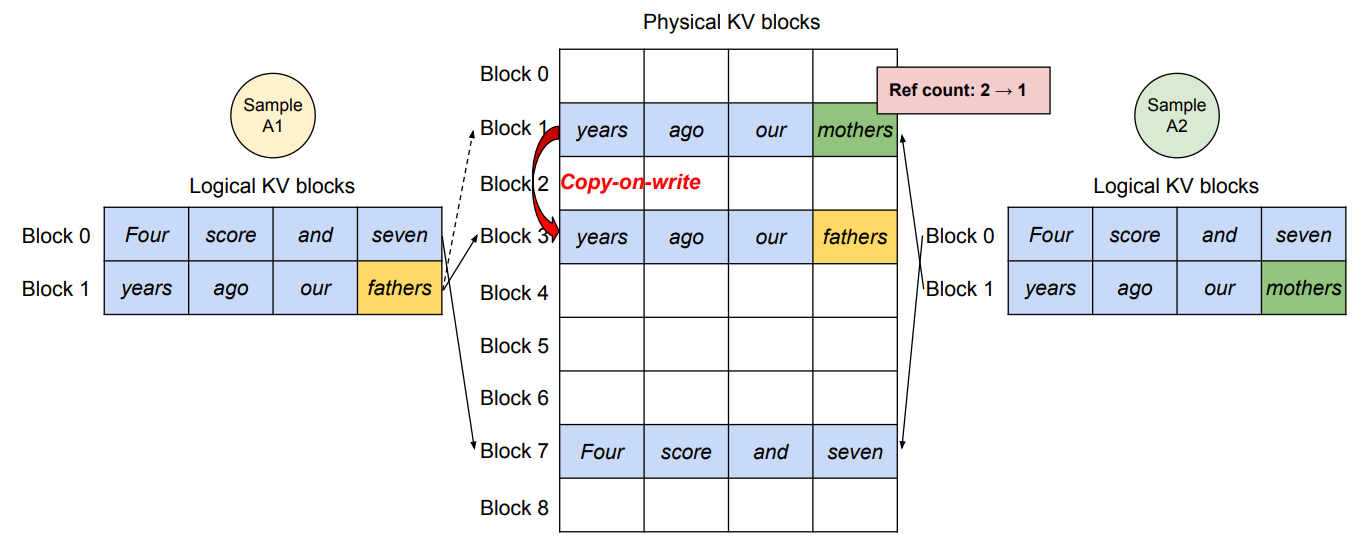
Copy-on-Write(COW)
vLLMでは、異なるビーム候補間で大半のブロックを共有できる
論理KVブロックと物理KVブロックの分離
複数候補が同じ履歴を共有している部分は、同じ物理ブロックを参照できる
参照カウント(reference count)
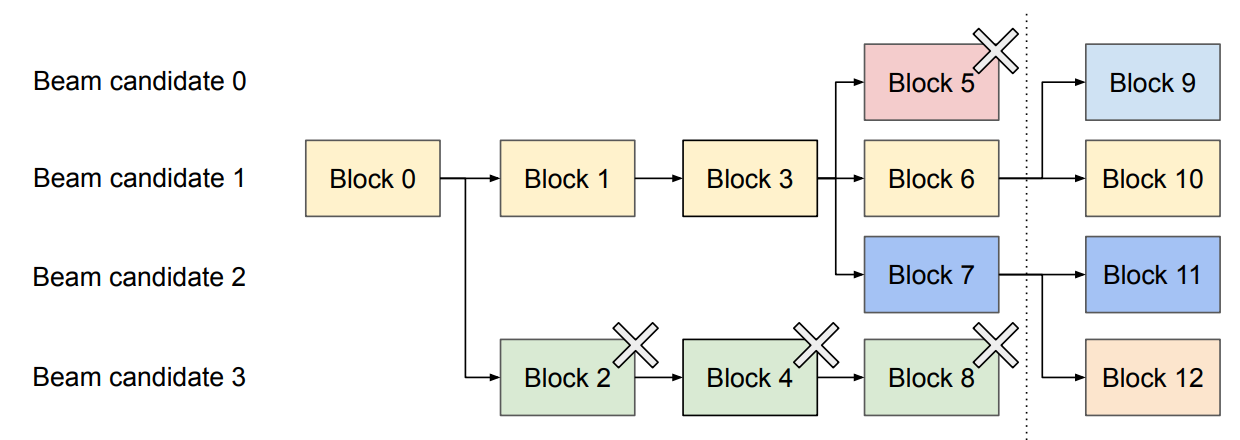
Copy-on-Write(COW)
従来のようにビーム候補間で大きなKVキャッシュを丸ごとコピーする必要がない
vLLMでは、各シーケンスを論理ブロック → 物理ブロックの共通マッピング層で扱うため、背後の共有パターンの違いを意識しなくて済む
デコーディング戦略そのものではないが、デコーディング戦略を実行する前提となるKVキャッシュ管理を効率化する
共有プレフィックス(Shared prefix)
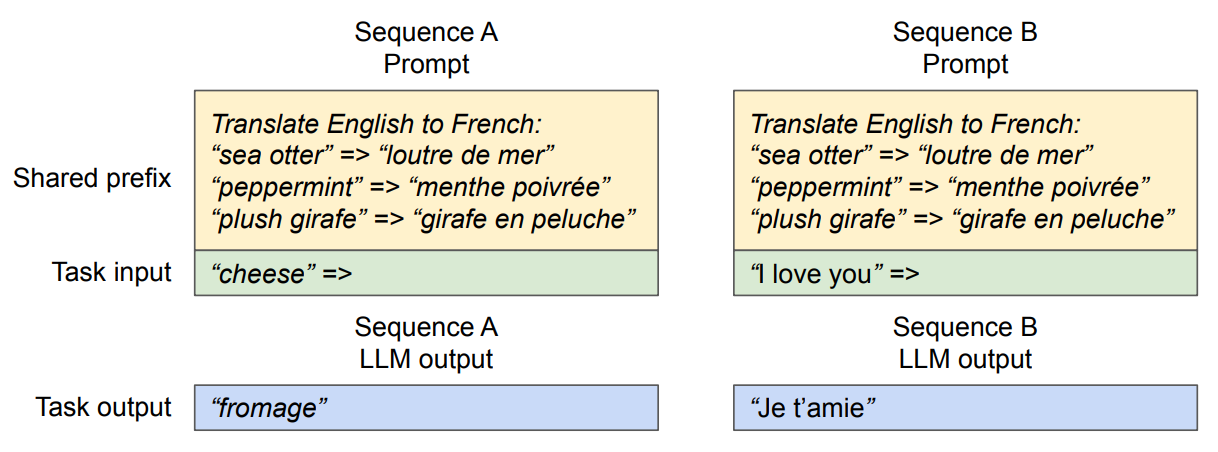
1つのシーケンスのKVブロックを部分退避しない
スワップ(Swapping)方式
再計算(Recomputation)方式
多くのLLMは、単一GPUの容量を超えるパラメータサイズを持つため、モデルを分散GPUへ分割し、モデル並列を実行する
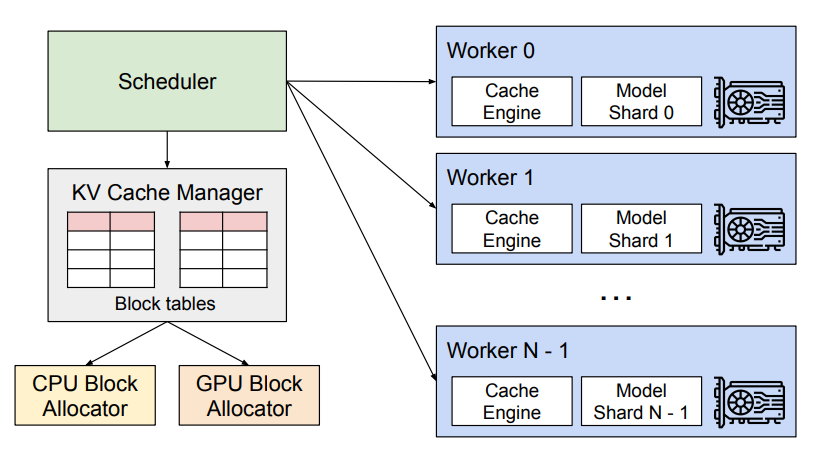
| 役割 | どこにある? | 何をする? |
|---|---|---|
| 集中型スケジューラ | 中央 | どのリクエスト・シーケンスを実行するか決める |
| KV Cache Manager | 中央側 | 各シーケンスの論理KVブロックが、どのGPUワーカー上のどの物理KVブロックに対応するかを管理する |
| GPUワーカー / Cache Engine | 各GPU | 実際のGPU DRAM上に物理KVブロックを確保・解放・読み書きする |