Bayesian Teaching Enables Probabilistic Reasoning in Large Language Models
L Qiu 著 · 15 Jan 2026 · 被引用数: 21・MIT, Meta, Google DeepMind, University of British Columbia, Vector Institute, Google Research, New York University
Link
Focus
Keyword
確率的信念(probabilistic beliefs)
- エージェントが「世界やユーザー嗜好について、不確実性込みで信念を持つ」こと。単一の答えを求めず、確率付きで候補を保持するのがポイント。
- 不確実性を残して分布(posterior)を持ち続ける
- 候補全体に確率を割り当て続ける、というベイズ的推論の肝。
- 対比:単一の最も尤もらしい仮説(reward function)を1つ選んで固定する(= argmax 仮説、MAP に近い)
信念更新(belief updating)
- 新しい観測(ユーザーの選択など)を得るたびに、信念(確率分布)を更新していくこと。論文は「既存LLMは信念更新が苦手」という問題設定から始まる。
規範的ベイズ推論(normative Bayesian inference)
- 「こう更新するのが最適」という規範(正しさの基準)としてのベイズ推論。人間・LLMの振る舞いがどれだけこの基準からズレるかを測るための「物差し」として使われます。
Bayesian Assistant(ベイズ的アシスタント)
- この論文での上界(upper bound)としての比較対象モデル。
- ユーザーの嗜好(reward function)に対して分布を持ち、ラウンドごとにベイズ則で更新して推薦を改善する。
reward function(報酬関数、ユーザー嗜好の表現)
- ユーザーが「価格は安い方が好き」「乗り継ぎは少ない方が好き」など、各特徴量に持つ嗜好の組み合わせを形式化したもの。
- フライト推薦タスクではこの reward function がユーザータイプを定義する(624通り)。
尤度(likelihood)
- ユーザーの選択とその嗜好タイプが「整合的かどうか」(the likelihood)が、 に相当する
- :選択肢集合
- :ユーザーの観測された選択(データ)
- :reward function
- 「整合的かどうか」で尤度を 0/1 にする(決定論的選択モデル)なら、典型的には
- 一般には 0/1 に限らず、確率的選択モデル(例:softmax choice)を仮定して 0〜1 の連続値になる
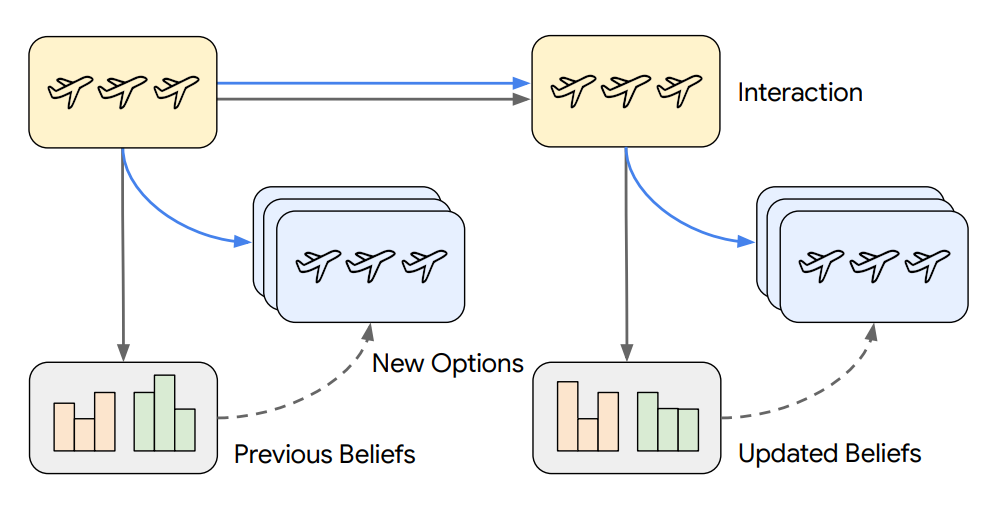
事前分布(prior)/事後分布(posterior)/一様事前(uniform / uninformed prior)
- 事前分布:ラウンド前の信念(事前に相当する、その時点の分布)
- 相互作用前の初期仮定
- :ラウンド (t-1) までに得られた観測データ(履歴)全体を表す
- 実験設定によっては、ユーザーが最後に与える正解フィードバックなども に含める流儀もある
- 一様分布:論文では初期事前として一様事前(すべての嗜好集合が等確率)を採用
- 事後分布:ラウンド後の信念:
- ベイズの定理を用いた事後確率の更新式
- :reward function
- :ユーザーの観測された選択(データ)
- 分母:正規化定数(周辺尤度)
- 前回の事後 を次回の事前として使うオンライン更新
- 事後分布は 事前(prior) と 尤度(likelihood) から更新された結果で、Bayesian Assistant はこれを逐次更新する
- :過去の履歴を踏まえた時点での reward function (r) への信念(=ラウンド の更新の事前)
- :その r が真なら、今回の選択肢集合 でユーザーが を選ぶ確率(=今回の証拠の尤度)
- :それらを掛けて正規化したもの(更新後=事後)
- 逐次更新の意味
- 前提:ラウンドごとの観測が のもとで条件付き独立だとすると(独立性仮定)
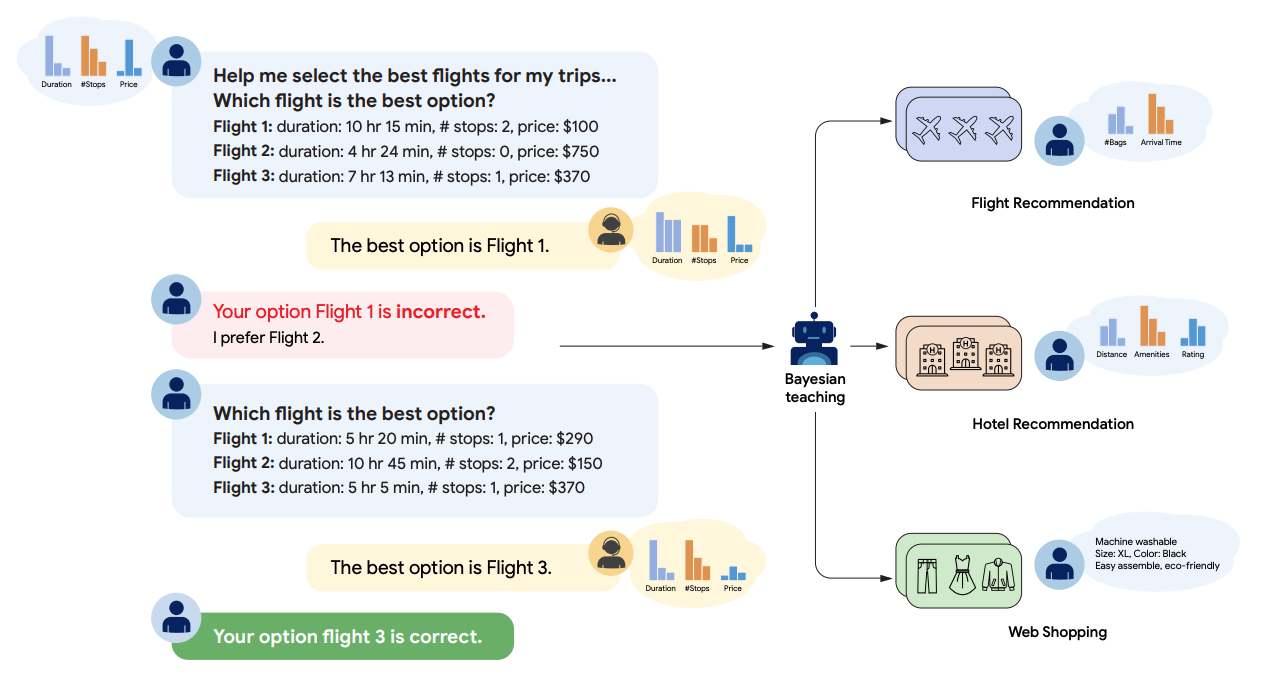
フライト推薦タスク(flight recommendation task)
- 本論文の主要ベンチマーク環境。
- ユーザーの選択から嗜好を推論して推薦する必要があり、「確率的信念更新」の評価がしやすいように設計されている。
Bayesian teaching(ベイズ・ティーチング)
- 本論文の中心的な提案。
- Bayesian Assistant の予測・振る舞いを模倣するようにLLMを教師あり微調整し、確率的推論(更新)の技能を移植する戦略。
oracle teaching(オラクル・ティーチング)
- Bayesian teachingの比較対象となる学習法。
- 常に正解を返す教師(oracle)との相互作用で学習させるが、論文では Bayesian teaching の方が一貫して有効と報告される。
neuro-symbolic / ハイブリッド(ニューラル・シンボリック手法)
- LLMを「翻訳役」にして、外部の記号的(ベイズ的)推論器で更新する系統との比較文脈。
- 本論文は「LLM単体でも近似的ベイズ更新を学べる」側を強調しつつ、ハイブリッドの利点(解釈性など)にも触れている。
Overview
WHAT(これは何?)
- 問題意識:LLMを「対話的エージェント」として使うときは、ユーザー行動などの新情報を受けて、確率的な信念を形成・更新しながら適応する必要がある。しかし既存のLLMは、その規範(Bayesian inference)の水準から大きく外れることが多い。
- 評価設定:フライト推薦タスク(複数ラウンド)で、ユーザーの嗜好(reward function)を直接教えず、ユーザーの選択から推論して推薦させる。規範上界として Bayesian Assistant(明示的に分布を保持しBayes則で更新するモデル)を定義し、LLM・人間と比較する。
- 主要結果:
- 既存のLLMは、1回の相互作用(interactions)後に性能が頭打ちになりやすく、ベイズ的な信念更新に弱い。
- しかし、後述の「Bayesian teaching」でLLMを追加学習すると、信念更新が改善し、タスク内・タスク外への一般化(ホテル推薦、Webショッピング等)も確認される。
WHY(提案手法の価値は?)
- 規範モデル(ベイズ推論)を“先生役”にして蒸留する
- 蒸留(distillation)
- Bayesian teaching を「別システム(Bayesian Assistant)の戦略を学習して模倣する」という意味で蒸留の一種として位置づけている。
LLMに規範的なBayesian Assistantの振る舞いを模倣させることで、信念更新能力を大きく底上げできる。
- 「正解を教える」よりも「規範モデルの推測を教える」ほうが効く
オラクル(常に正解を提示)で学習するより、Bayesian Assistantの「根拠ある推測」(初期は外すこともある)を模倣させる方が一貫して良かった。
- 事後学習(Post-Training)の一般化の実利:
- 一般化(generalization)
- 学習したフライト推薦を超えて、ホテル推薦・ウェブショッピングなど別ドメインにも“確率的更新スキル”が転移することを実験で示す。
現実寄りタスク(Webショッピング)のように、記号的に完全なベイズモデルを作りにくい領域でも、いったん合成環境で学ばせた「推論様式」が転移する可能性を示した。
- 設計含意:
「LLM+記号モデル」の関係において、記号モデルを実運用で常に組み込むのではなく、記号モデルのふるまいを教師信号として蒸留し、LLMに近似させるという開発戦略が有望、と示唆する。
WHERE(技術のキモはどこ?)
- 上界(教師)を作る:
- 事前分布(例:一様)
- 尤度(ユーザー選択との整合)
- Bayes則更新
フライト推薦の制御環境では嗜好タイプ(reward function)が有限(例:624通り)なので、Bayesian Assistantが
で 「reward function上の分布」を厳密に更新できる。
- 学習データの作り方:
- Oracle teaching:正解推薦を常に出す教師
- Bayesian teaching:Bayesian Assistantの推薦(不確実性を持つゆえに外すこともある)を出す教師
- 狙ったスキル(確率的推論戦略)を教えるために構成したテキストで追加学習する
ユーザー×複数ラウンドの相互作用ログを大量生成し、それを 教師ありファインチューニングのデータにする。比較のために2通りの教師を用意する。
- 評価の観点が「推論様式」に寄っている:
- マルチラウンド相互作用(multi-round interaction)
- 1回で当てるのではなく、複数回のやりとりで情報を集めて改善する前提の設定。
- 論文は「多くのLLMは1回目以降あまり改善しない(plateau)」を主要な観察として示す。
最終精度だけでなく、ラウンドを経て改善するか否か、Bayesian Assistantとの一致度が上がるか、情報量(informativity)に感度が出るか、などで 「確率的信念を更新しているか」を見ている。
- 言語化した信念→外部手続きで推薦というハイブリッドも検討:
LLMに嗜好の信念を明示的に言わせ、それを使って推薦を導くと改善する、という示唆も出している(付録Bの方向)。