
Computer Agent Arena | XLANG Lab
B Wang 著 · 07 Apr 2025 ・The University of Hong Kong・University of Waterloo・UC Berkeley・Stanford University・The Ohio State University・Amazon AWS Bedrock
Focus

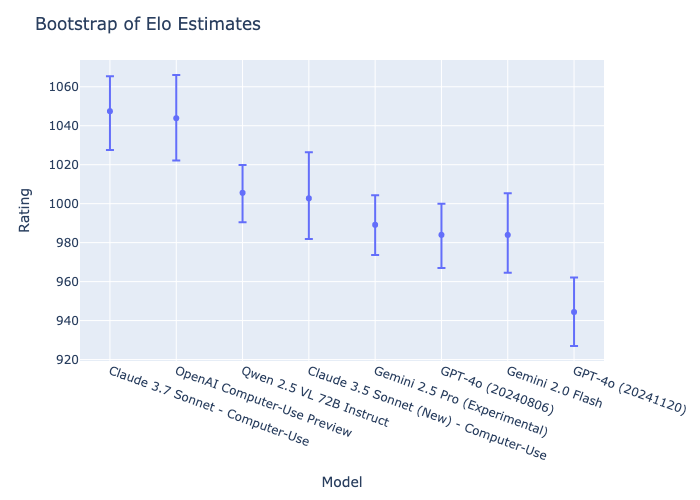
95%信頼区間を持つEloスコアランキング
Keyword
Computer Agent Arena
実際のコンピューター利用タスクを実行するLLMおよびVLMベースのエージェントを評価するためのオープンプラットフォーム
- コンピューター利用タスクには、コーディング、データ分析、動画編集などの専門的なワークフローから日常的な作業まで含まれる
イマーシブ環境 immersive environments
ユーザーが、コンピューターやデジタル環境と直接的かつ没入的に相互作用できる環境のこと
- LLMやVLMを搭載したデジタルエージェントが、没入的な環境の中でユーザーの指示を具体的なタスクやアクションに変換できるようになっている
- 例:実際のデスクトップ環境やウェブブラウザ内で、エージェントがユーザーの指示に基づいて直接的に操作を行えるような環境
SWEAgent
- 言語モデル(LM)とエージェント-コンピュータインターフェース(ACI)で構成された、ソフトウェアエンジニアリングタスクを自動化するためのシステム
- ソフトウェアエンジニアリングにおける複雑なタスクを自動化することを目指している。具体的には、コードの検索、ナビゲーション、編集、テスト実行などの作業を自律的に行えるように設計
Computer-Using Agent(CUA)
- OpenAI が開発した、LLMまたはVLMを基盤として、人間がコンピューターを操作するのと同じように、、ユーザーの指示に基づいたタスクを実行できるAI エージェント
- GPT-4o の視覚能力と、強化学習による高度な推論を組み合わせている
- 画面に表示される生のピクセルデータを処理して内容を理解
- 人間と同様に、仮想マウスとキーボードを使用して、クリック、スクロール、入力などのアクションを実行
- 特定の OS やウェブサイトに特化した API を使用することなく、多様なデジタル環境で柔軟にタスクを実行可能
- 複数ステップからなる複雑なタスクをナビゲートし、エラーを処理し、予期せぬ変更にも適応する
- OSWorld ベンチマークにおいて 38.1% の成功率を達成
- ウェブベースのタスクにおいては、WebArena で 58.1%、WebVoyager で 87% の成功率を達成
OSWorld
- Ubuntu、Windows、macOS などの完全なオペレーティングシステムを制御する能力を評価するベンチマーク

WebArena
- ブラウザを使用して実世界のタスクを完了するウェブブラウジングエージェントのパフォーマンスを評価するベンチマーク
Claude 3.7 Sonnet
- 2025年2月25日にAnthropicによって発表された、同社で最も知的な最新のモデルであり、市場初のハイブリッド推論モデル
- 特にコーディングとフロントエンドWeb開発で著しく改善
Chatbot Arena
- LLMの性能を、多数のユーザーからの評価を通じて比較・ランキングするためのオンラインプラットフォーム
- 言語モデルの能力をクラウドソーシングによって評価する先駆け
- ユーザーは、匿名化された異なるモデルからの回答を受け取り、どちらの回答がより良いかを判断することで、モデルの相対的な性能が評価される
- 評価結果は、Eloアルゴリズムを用いてスコア化され、リーダーボードとして公開される
- 主にテキストベースでの言語モデルの評価に特化しており、現実世界の複雑なタスクにおけるエージェントの行動や能力を直接的に評価することはできない
Eloスコア
- 異なるエージェント間の相対的な性能を数値化するための指標
- 対戦結果に基づいて動的に変化し、エージェントの相対的な強さを継続的に反映する仕組み
- 期待スコア
- エージェントAがその対戦でどれくらいの成績を期待されるかを表す期待スコアを計算する
- :エージェントAとBのEloレーティング
- エージェントBのレーティングがエージェントAのレーティングよりも高いほどは低くなる
- Computer Agent Arenaでは初期レーティングの値をいくつに設定するかは示されていない(初期レーティングの設定値はゲームによって様々で、例えば1500や1000とする)
- レーティングの更新
- エージェントAが期待よりも良い成績 を収めた場合、レーティングが上昇する
- エージェントAのEloレーティングは、実際のスコアと期待スコアの差に基づいて更新される
- :エージェントAが対戦に勝った場合は1、負けた場合は0、引き分けた場合は0.5になる
- :レーティング調整要素。この値が大きいほど、対戦結果がレーティングに大きく影響する。Computer Agent Arenaでは常に4に設定している
Overview
WHAT(これは何?)
- XLANG Labが開発した、LLMおよびVLMを基盤とするエージェントが実際のコンピューター利用タスクを実行する能力を評価するためのオープンなプラットフォームComputer Agent Arenaの紹介
- このプラットフォームは、クラウドベースの仮想マシン上でホストされ、Windows、Ubuntu、そしてまもなくMacOSをサポート予定
- ユーザーは、Google Docs、Slack、YouTubeなどの厳選されたプリセットアプリケーションやウェブサイトを選択したり、ファイルのアップロードや特定のサイトを開くなどのクイックスタートアクションを利用したり、あるいは通常のマウス操作やキーボード入力を行うことで、評価環境をカスタマイズ可能
WHY(提案手法の価値は?)
- コーディング、データ分析、動画編集などの専門的なワークフローから日常的な作業まで、現実世界の多様なコンピューター利用タスクにおけるLLM/VLMベースのエージェントの性能を評価する
- 評価結果はEloアルゴリズムに基づいたリーダーボードで公開され、コミュニティがエージェントの能力を比較し、競争を通じて向上を促すことが可能
- Eloスコア 参照
WHERE(手法のキモはどこ?)
- このプラットフォームの重要な点は、単なる言語応答能力ではなく、実際のコンピューター環境内で多様なアプリケーションやウェブサイトと対話し、タスクを完了する能力を直接的に評価する点
- 既存のLLM評価プラットフォーム(Chatbot Arenaなど)や、限定的なタスク範囲のベンチマーク(OSWorld, WebArenaなど)では捉えきれない、実用的なエージェントの性能の評価を実現
- 評価環境の初期状態をカスタマイズ可能な初期セットアップハブを備えている