
大規模言語モデルにおける特異性: Idiosyncrasies in Large Language Models
Title
Idiosyncrasies in Large Language Models
M Sun・17 Feb 2025・Carnegie Mellon University
Code
llm-idiosyncrasies
locuslab • Updated Feb 24, 2025
Reddit
YouTube
Focus
モデルの類似性の推論結果

モデルの特徴的なフレーズ

Keyword
N-way classification(N方向分類→N値分類)
- 与えられた入力がN個の異なるクラスのどれに属するかを予測するタスク
- 例:5つのLLM(ChatGPT、Claude、Grok、Gemini、DeepSeek) があった場合に、あるテキストがどのLLMによって生成されたものかを当てるタスク
- 分類器は与えられたテキストを分析し、最も可能性の高い生成元を予測
Ultrachat
- 2つのChatGPTによって生成された対話データセット
- 2 つの別々の ChatGPT Turbo API を呼び出し、1 つはユーザーの役割を果たしてクエリを生成し、もう 1 つは応答を生成した。
- 慎重に設計されたプロンプトを使用してユーザーモデルに指示し、人間のユーザー行動を模倣し、2つのAPIを繰り返し呼び出す。
Overview
WHAT(これは何?)
LLMごとの特異性(モデルを識別できるような出力の独特なパターン)の存在を実証するため、その程度を定量化する合成タスクの設計を行なった
- 方法:事前学習済みの埋め込みモデルを、単純にLLM出力テキストでFineTuningして分類器とし、そのテキストを生成したソースLLMを予測させる
WHY(研究の価値は?)
- 異なるLLM間で生成されたコンテンツを分類する研究はこれまでほとんど行われてこなかった
- 昨今、LLMが生成したコンテンツの起源・出所を理解することが重要になってきている
- LLMに明確な特異性が存在することを示した
- 特異性の研究成果
- 特異性は単語レベルの分布に根ざしている
- LLMが生成した応答の単語をランダムに並び替えた後でも、分類精度はほぼ低下しない
- 外部LLMによってテキストを書き換えたり、翻訳または要約された場合でも特異性は持続し、意味的内容にも符号化されている
- 合成データでのトレーニングやモデルの類似性推論を行い、その影響が広範にわたることを示した
WHERE(研究のキモはどこ?)
単純な埋め込みモデルのFineTuningに基づく分類器で、ソースLLMの特定が可能であることを示すため、さまざまな合成タスクを設計した

- N個のモデルから2つを選ぶすべての可能な組み(C2N)を2値分類するタスク
- N個のクラスの中から1つを選ぶN値分類タスク
モデルファミリー間の比較
このタスクで著しく高い精度を達成できることを発見した
- LLMに明確な特異性が存在する
- acc.が高い:LLMペア間の差異が大きい:高いacc.は、そのLLMペア間にはっきりとした違いがあることを示す
- acc.が低い:LLMペア間の類似性が高い:逆に、acc.が低いペアは、互いに類似した特徴を持つことを示す
- 5値分類:検証データで97.1%の分類精度を達成
- チャンスレベルで20%の正解率(完全にランダムに選択した場合で20%の正解率)と比較して偶然では決して得られない精度と言える
同一モデルファミリー内での比較
同一ファミリーのモデルは通常、事前学習データセットや最適化スケジュールなどの共通の学習手順を共有している
同一ファミリー間の分類タスクはより困難だったが、チャンスレベルをかなり上回る精度を維持した
- 4つのデータセット全てで分類器を評価
学習分布外の応答への汎化性能
4つの多様なデータセットから教師あり学習型(instructカテゴリの)LLMの応答を収集
- UltraChat
- Cosmopedia(Ben Allal et al., 2024)
- LmsysChat(Zheng et al., 2024)
- WildChat(Zhao et al., 2024))
各データセットのLLM応答ごとに分類器を訓練し、4つのデータセット全てで分類器を評価
- 訓練に使用したデータセットとは異なる、複数の多様なデータセットで評価を行う
- 例:UltraChatのLLM応答データで分類器を訓練し、Cosmopedia・LmsysChat・WildChatのLLM応答データの組みで検証する
- 異なるデータセットに対しても分類器は高い汎化性能を示した
- 非常に堅牢で転移可能なパターンを学習している

異なる条件による分類精度の比較を行った
- プロンプトに応答の長さやフォーマットに関する制約を加える
- 長さの制御:100語以内の1段落で、簡潔な応答を提供してください。
- 形式の制御:斜体や太字のテキスト、リスト、マークダウン、HTMLフォーマットを使用せず、プレーンテキストのみで応答を提供してください。
- 長さやフォーマットを揃えても、
- LLMの特徴がテキストに深く組み込まれており、長さやフォーマットの表面的な制約にもかかわらず持続していることを示唆
プロンプトによるLLM出力の制御
以下のプロンプト制御を加えた、N個のモデルの出力をN値分類

- テキスト埋め込みモデルへの入力トークン数に制御を加える
- チャットAPIと教師あり学習型LLMでは、単一のテキストトークンだけでも約50%の精度で分類
- LLMが応答の最初の単語に、そのLLM特有の情報をエンコードしている可能性を示唆する
テキスト埋め込みモデルの入力長の制御
各応答を左から右への順序で固定数のトークンに切り詰めた入力で分類を実施した

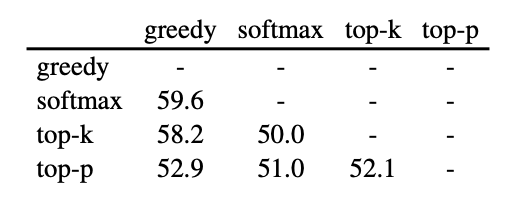
- デコーディング戦略の調査(Llama3.1-8b Instruct)
- 貪欲デコーディング、温度付きソフトマックス、top-k、top-pサンプリングという4つの広く使用されているサンプリング手法を使用
- 同一LLMによって生成された応答を区別する精度は比較的低く、全設定における最高精度は59%
- 5つの異なる温度(T = 0, 0.25, 0.5, 0.75, 1)でのソフトマックスサンプリングを区別するより細かい5クラス分類では、37.9%の精度
- 同一LLMからの出力がデコーディング戦略に基づいて容易に区別できない
サンプリング手法の変更
LLMから一連の応答を生成し、LLM2vec埋め込みモデルを微調整して、各応答の生成に使用されたサンプリング手法を予測
- 事前学習済み埋め込みモデルの調査
- ELMo(Peters et al., 2018)
- BERT(Devlin et al., 2018)
- T5(Raffel et al., 2020)
- GPT-2(Radford et al., 2019)
- LLM2vec(BehnamGhader et al., 2024)
- より高度なシーケンス埋め込みモデルほど分類精度が高い
テキスト埋め込みモデルの変更
以下の埋め込みモデルで分類精度を比較
デフォルト埋め込みモデルは、LLM2vec埋め込みモデルの微調整

- 必要な学習データの量の調査
- より多くの学習サンプルで学習するほど精度が向上
- わずか10個の学習サンプルでも、意味のある精度(例:教師あり学習型LLMで40.3%)を達成
- 分類性能は約10,000個の学習サンプルで収束
学習データサイズの変更
LLMが生成するサンプル数を変化させ、同じ総イテレーション数で分類器を学習

言い換えや翻訳など、意味を保持しながら単語分布を変化させる実験
- LLM出力間の語彙的な違いを定量化
- ROUGE-1(Lin, 2004)
- 単語がどれだけ重複しているかを測る
- Precision = (共通する単語数) / (ChatGPTのテキストの単語数)
- Recall = (共通する単語数) / (Claudeのテキストの単語数)
- F1スコア = 2 * (Precision * Recall) / (Precision + Recall)
- 上記のF1スコア = ROUGE-1スコア
- ROUGE-L(Lin, 2004)
- BERTScore(Devlin et al., 2018)
- 2つの異なるLLM(across LLM)と同一LLM(within an LLM)からの応答を比較
- 同一LLMからの応答と比べて、2つの異なるLLMの方が、類似度がより低い
テキスト類似度
同じプロンプトに対して2つの異なるチャットAPIモデルが生成したすべての応答ペアの類似度評価
類似度指標

単語と文字、マークダウン形式要素、意味的内容に関するアブレーション実験
- 単語と文字
- LLMが生成した応答から句読点、マークダウン要素、過剰な空白などの特殊文字を削除
- 単語と文字の効果を他の要因から切り離す
- 単語レベルと文字レベルの2つのシャッフル戦略
- 自然な順序を崩す
- 分類器に生のテキスト統計からパターンを学習させる
- 特殊文字を除去して学習させた分類器は、元の応答を使用した場合と同程度の精度
- 単語をシャッフルした応答を学習させた分類器も、元の応答と同等の高い精度
- 文字をシャッフルすると性能が大幅に低下する
- 文字はLLMの特徴にほとんど寄与していない
- LLMで最も頻繁に使用される上位20単語(左)は各モデルで異なるパターンを示す
- Claudeは他のチャットAPIと比べて、"the"、"and"、"to"、"of"などの単語の使用頻度が大幅に低い
- LLMを区別する上で、特殊文字や単語の順序は本質的ではなく、単語の選択がモデル間の顕著な特徴を反映している
- 文字の頻度 letter frequencies(右)は非常に類似している
- TF-IDF特徴量に割り当てられたcoef(係数)の絶対値の大きさによる、特徴量(単語)の重要度ランキング
- 文章の中での接続や強調として機能するフレーズが多くみられる
- ChatGPTは「such as」、「certainly」、「overall」を生成する傾向があり、Claudeは「here」、「according to」、「based on」を好む
- ChatGPTは「certainly」や「below is」で応答を開始する一方、Claudeは通常「according to the text」や「based on the text」のようなフレーズを使用して元のプロンプトを参照する
- チャットAPIの応答における文頭単語の選択分布
- Instruct LLMとbase LLMにおける文頭単語の選択分布
テキストのシャッフルの影響

出現頻度の高い単語の比較
モデル間で明確な違いが見られ、頻出する英単語でさえも異なるパターンを示す

特徴的なフレーズの特定
N個のモデルそれぞれに対し、応答に含まれる単語の出現頻度のみを考慮した(単語ごとの)TF-IDF特徴量を作り、ロジスティック回帰モデルでN値分類させる




- マークダウン形式
- 分類器はチャットAPIで73.1%、Instruct LLMで77.7%という高い精度を達成
- base LLMの応答に対する分類精度は、チャンスレベルの推測(25%)に近い値
- base LLMが通常プレーンテキストで応答を生成する傾向があるため
- Claude(黄色)は太字テキストと見出しの集計分布においてゼロの位置で高い密度を示す
- 太字テキストや見出しを使用せずに多くの応答を生成している
- 一方、他のLLMはゼロの位置での値が低い
- これらのフォーマット要素でテキストを装飾する傾向がある
- ChatGPTは箇条書きの中の各要点を太字で強調し、タイトルをマークダウンの見出しで強調する傾向がある
- Claudeはシンプルな箇条書きと番号付きリストでテキストをフォーマットする
一般的なマークダウン要素の影響
LLMの出力から以下のフォーマット要素のみを保持し、他のテキストを「xxx」というマーカーに置き換えることで変換する
(1) 太字テキスト、(2) イタリック体テキスト、(3) 見出し、(4) 番号付けリスト、(5) 箇条書き、(6) コードブロック

各応答におけるマークダウンフォーマット要素の出現回数
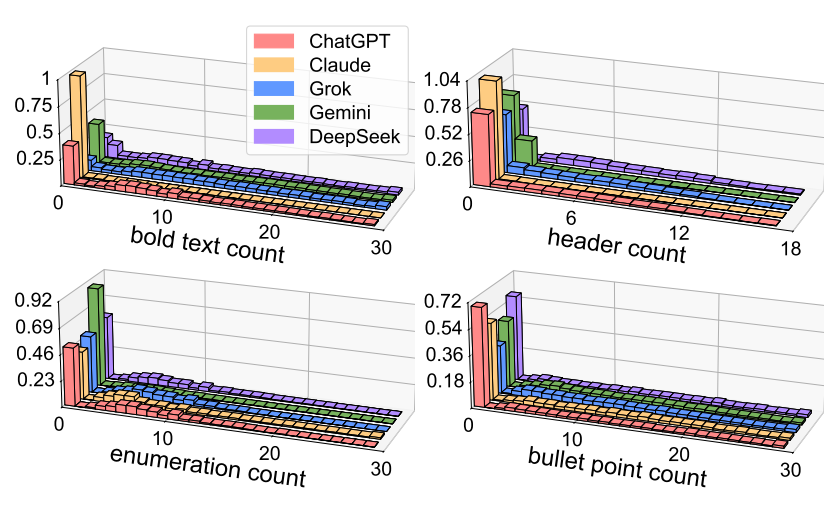
ChatGPTとClaudeがマークダウンでどのように応答を構造化しているか

- 意味的内容
- 言い換え:元のテキストの意味を維持しながら、上記のテキストを言い換える
- 翻訳:上記のテキストを中国語に翻訳する
- 要約:上記のテキストを1段落で要約する
- 言い換えられた(paraphrased)LLMの応答で訓練された分類器は、オリジナルの応答を使用した場合と同様の精度
- 翻訳されたテキストを使用した場合でも、分類器はLLM間の区別が可能
- 要約されたテキストの場合、顕著な精度低下(38%以上)が見られるものの、結果的な性能は依然としてチャンスレベルを大きく上回る
- LLM審査員が、2つの異なるモデルが(同じプロンプトに対し)生成した応答を分析する(例:文体や内容について)
- 最後に、LLM審査員が、箇条書きでこれらの分析を要約する
- ChatGPTは説明的な言語、洗練されたマークダウンフォーマット、詳細な内容が特徴である一方、Claudeは簡潔な文体、最小限の構造、要約された内容を重視している
- 各LLMの独自の表現方法
- ChatGPTは洗練されたマークダウンフォーマット、説明的な言語を用いる
- 詳細で深い説明を好む傾向がある
- Claudeは簡潔な文体、最小限の構造、要約を用いる
- より簡潔で直接的な応答、明確さを好む傾向がある
テキストの書き換え
文章スタイルの要因を分離するため、別のLLM(例:GPT-4o mini)を活用してLLMの応答を書き換えた
書き換えたLLMの応答で訓練された分類器の精度

自由形式の言語分析
別のLLM(例:ChatGPT)を審査員として採用し、LLMの出力に対して自由形式の説明的な特徴付けを行う
ChatGPTとClaudeに関する自由形式の言語を分析した結果

- 合成データによるSFTの影響の調査
- 同じ合成データセットでのSFTにより、分類精度が96.5%→59.8%まで大幅に低下した
- 同じ合成データセットで異なる2つのモデルを別々のSFTすると、2つのモデルの特異性が類似して分類が難しくなる
- UltraChatプロンプトを使用して2つのInstruct LLM(Llama3.1-8BとGemma2-9B)から応答を生成する
- 2つの応答セットで、2つのQwen2.5-7BベースLLMをそれぞれSFTする
- 2つのSFTモデル(Qwen2.5-7B)からの応答は、98.9%の精度で分類できた
- 異なるソースモデルで作成した合成データで、同じ2つのモデルを別々にSFTすると、各ソースモデルの特異性が伝播して分類が容易になる
同じ合成データで2つの異なるモデルをSFTする
Ultrachatで、2つのベースLLM(Llama3.1-8bとGemma2-9b)に対してSFTを実施
異なる合成データで2つの同じモデルをSFTする
- モデルの類似性
- N個のLLMのセットのうち1つのLLMを除外し、残りのN-1個のLLMからの応答で分類器を訓練
- 除外されたLLMの応答を分類器に入力し、N-1個のLLMのうちどれに分類するかを評価
- このプロセスをN個のモデルそれぞれに対して繰り返す
- N個のモデル:
- 5つのチャットAPIモデル + オープンウェイトのPhi-4(Abdin et al., 2024b)
- Phi-4は、web コンテンツや生コードではなく大量の合成データで訓練したMicrosoft Researchのモデルで、GPT-4oを教師モデルとする以前のPhiモデルをベースに改良された
- Claude、Grok、Geminiについては、その出力がChatGPTとして分類された
- ChatGPTとDeepSeekからの応答は、それぞれ55.9%と76.0%の割合でPhi-4からのものと分類される
- 一方で、Phi-4の出力の大部分はChatGPTまたはDeepSeekから生成されたものとして分類される
- Phi-4のトレーニングに使用された合成データに、ChatGPTの個性が反映されている可能性を示唆している
モデルの類似性推論
除外されたLLMからの出力に対して5方向分類器を評価し、予測されたソースモデルの分布

Experiment Settings
実験設定
- LLM出力を分類する合成タスクを構築
- 個の出力セットに対して、どのLLMがその出力を生成したかを予測する
- :N個のLLM
- 各は入力プロンプトを受け取りテキスト補完を出力
- :各LLM によって生成された出力
- 各LLMから多数のテキスト出力をサンプリングし、どのモデルがどのテキストを生成したかを認識するように分類器を訓練する
- 同じプロンプトセットを使用
- 異なるLLMからの出力が、同じ分布から得られたものであれば、分類精度はランダムな推測以上にはならないはず
- → LLM出力の分類において、驚くほど高い精度が観察された
- 各LLMと所与のプロンプトデータセットに対し、11,000のテキストシーケンスを収集し、10,000を訓練用、1,000を検証用に分割
- UltraChat(Ding et al., 2023)から出力を生成
- 指示への応答を生成
- 5値分類の検証データで97.1%の精度を達成
- GPT-4o(OpenAI, 2024)
- Claude-3.5-Sonnet(Anthropic, 2024)
- Grok-2(xAI, 2024)
- Gemini-1.5-Pro(Google, 2024)
- DeepSeek-V3(DeepSeek-AI, 2024)
- Llama3.1-8b(Dubey et al., 2024)
- Gemma2-9b(Riviere et al., 2024)
- Qwen2.5-7b(Qwen et al., 2024)
- Mistral-v3-7b(Jiang et al., 2023)
- FineWeb(Penedo et al., 2024)から出力を生成
- 新しいテキストを生成
- 大規模なテキストコーパスで事前学習されたもの(事後学習なし)
chatカテゴリ(API)
instructカテゴリ
baseカテゴリ
- 単純なテキスト埋め込みモデルのFineTuningに基づく分類器を使用