Reinforcement Learning Finetunes Small Subnetworks in Large Language Models
S Mukherjee 著 · 18 Dec 2025 · 被引用数: 29・NeurIPS 2026・University of Illinois
NeurIPS
Focus
公開されている代表的なチェックポイントにおける、SFT 段階と RL 段階の累積勾配の比較
- RL では更新されるパラメータ数が大幅に少ない可能性がある
- RLがSFTよりも事前学習済みモデルの能力をよく保持するという、下記の知見を指示する
Keyword
Parameter update sparsity
- RL微調整で、全パラメータのうち一部だけが実質的に更新される現象。
- 更新スパース性の定義
- は非ゼロ要素の数を数える
- 注意:
- 更新量 がスパースであっても、微調整後のモデル がスパースであることを意味しない
- とする。
- 全部の要素が非ゼロなので、密なベクトル
- 微調整後に、になったとする。
- このとき差分は、になる。
- つまり、変わったのは 1 要素だけである。 この差分はスパースと言える。
- ただし微調整後の 自体は、なので、依然として密である。
例:
Accumulated gradients(累積勾配)
- 各学習ステップで計算される勾配 、またはそれを学習中に累積したもの
- 「どのパラメータに学習信号が来たか」を見る量
- SFTとRLの更新密度の比較に使われる。
- 本論文では、学習中にどれくらい広く勾配・更新信号が発生したかを見るための補助的な観察に用いられる
- なぜ累積勾配の更新を見るの?パラメータの更新だけでよくない?
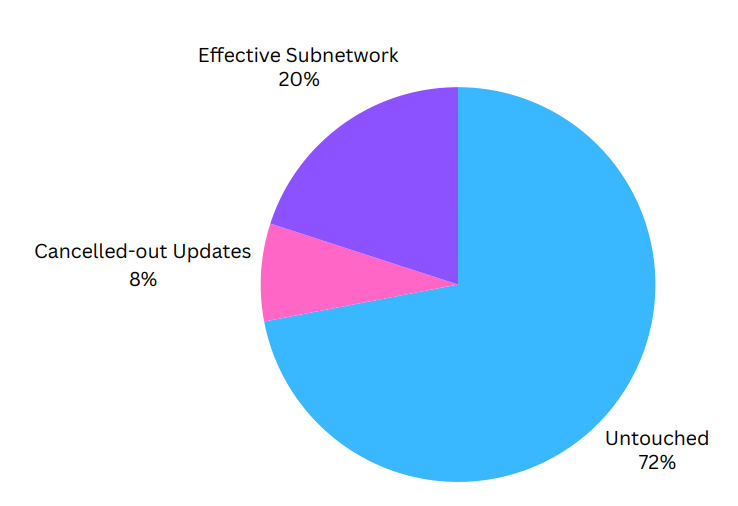
- 非ゼロ勾配を受け取るものの最終的には相殺されたケースを特定するため
- 一度は更新されたが最終的にはサブネットワーク外にある重み
- PRIME では、72% のパラメータは一度も更新されず、8%は勾配が互いに打ち消し合い、20%は一貫して更新されるサブネットワークを構成している
- その重みは accumulated gradients / training dynamics 上は動いたと言える一方で、最終的なparameter update(パラメータ更新)としては変わっていない
- 途中で非ゼロ勾配を受けるが、正負の更新が打ち消し合い、最終的には差分が残りにくい現象。
Gradient cancellation
Sparse subnetwork
- RLによって更新される小さなパラメータ集合。
- 論文では全体の5〜30%程度とされる。
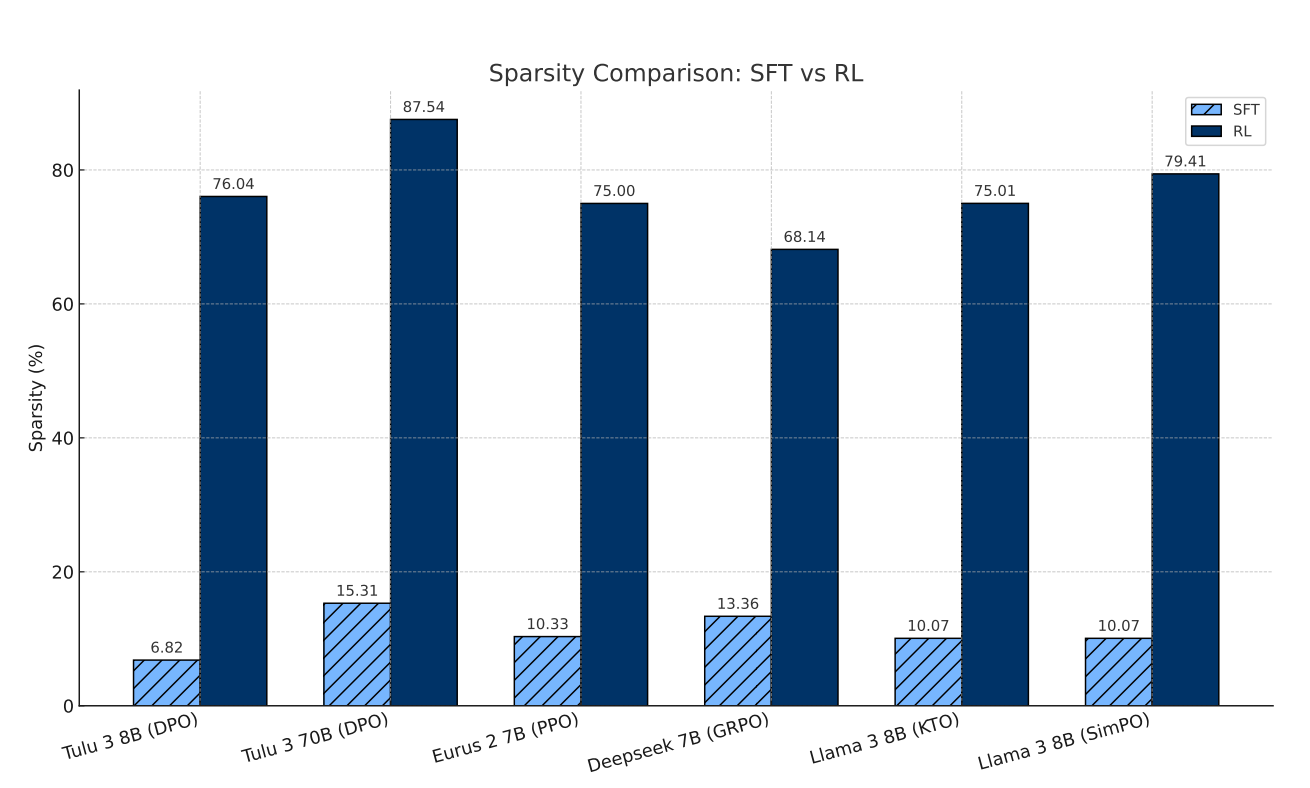
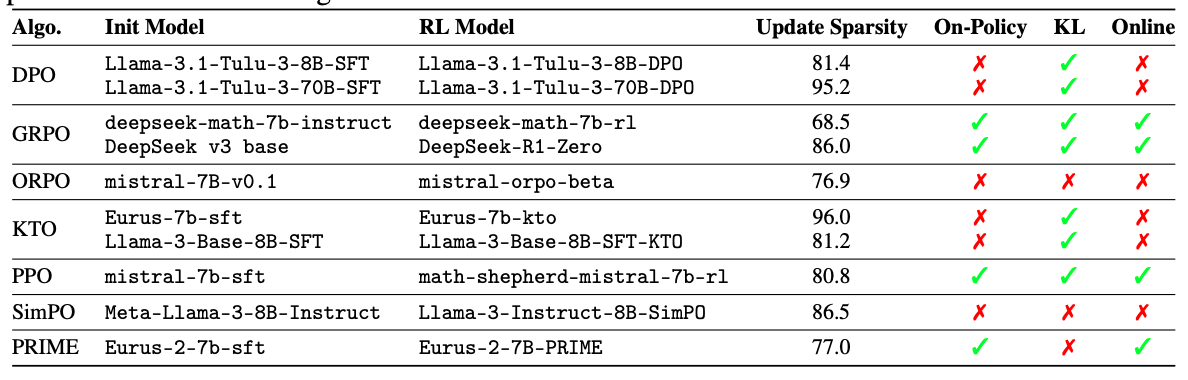
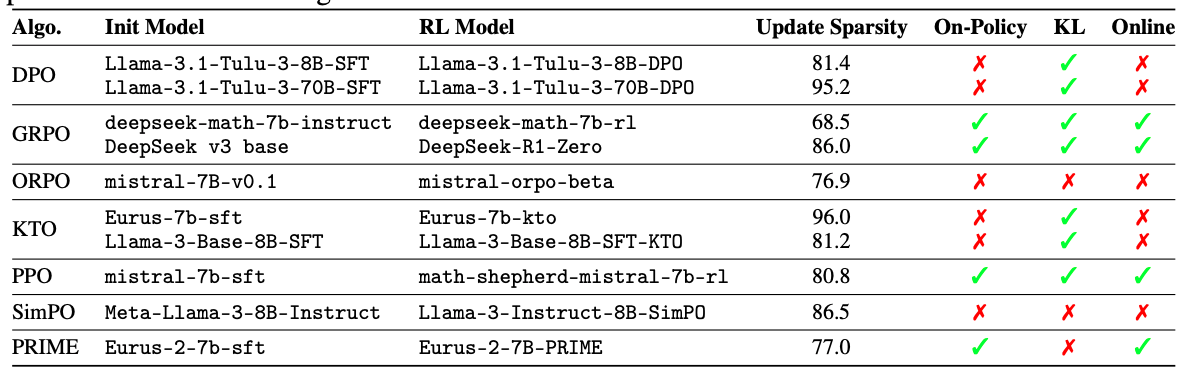
- 異なる RL アルゴリズムにおけるパラメータ更新スパース性
- すべてのモデルで、RL後も少なくとも 68.5%、多くの場合はそれ以上のパラメータが変化しないまま
- ※ 数値精度の限界を考慮して、2つの bfloat16 値の絶対差が を超えない場合、それらを等しいものとして扱う
- bfloat16の数値誤差を考慮して、微小差分を同一とみなす許容誤差。
- 本論文では主に が使われる
bfloat16 tolerance
Subnetwork finetuning
- 最終的に更新されたサブネットワークだけを再度微調整する実験設定。
- フル微調整モデルに近い性能とパラメータ値を再現できる。
活用例
- 更新すべきパラメータ集合を次のアブレーション研究で更新候補として使い回す
- 毎回フルモデルを更新して比較する代わりに、前回見つかった共通サブネットワークだけを更新する
- 共通サブネットワーク + 少し追加の候補だけを更新する
- 共通サブネットワークを除いた部分だけを更新して性能低下を見る
- 更新対象パラメータを探索するコストの節約
- 実行コストが高いRL手法(PPO)を実行する前にコストの低いRL手法で先に動きやすいパラメータ候補を見つけておく
- 通常のPPOでは、全パラメータに対して勾配を計算し、 optimizer state も持ち、どのパラメータが本当に効くかを結果的に学習中に発見する
- しかし DPO で先に候補を見つけておけば、PPO では最初から、「このあたりだけ動かせば十分かも」という制約付きで学習できる
- コストの高い方法ではその候補周辺だけを更新する
Lottery Ticket Hypothesis
- 大きなニューラルネットワークの中には、元の巨大モデル全体を使わなくても、単独で学習すれば同程度の性能を出せる「小さな当たりサブネットワーク」が埋まっているという仮説。
- 大きなネットワークの中に、単独で学習しても性能を出せる小さなサブネットワークが存在する
- 本論文はこれを RL微調整の文脈へ拡張している。
Low-rank update
- 更新が低次元部分空間に制約されること。
- 本論文では、RL の更新は低ランクではなく、スパースだがほぼフルランクとされる。
Full-rank update
- 更新行列が表現可能な空間をほぼ広く張っていること。
- 少数パラメータの更新でも、表現空間としては広い可能性を示す
- RLの更新は低ランク部分空間に収まっているのではなく、パラメータ行列が表現できる部分空間のほぼ全体を張るようなパラメータの一部に局在している
RL finetuning
- LLMの事前学習後に、強化学習で性能やアラインメントを改善する微調整。
PPO
- RLHFの代表的な方策最適化アルゴリズム。
GRPO
- DeepSeek系で使われるRLアルゴリズム。
DPO
- 報酬モデルを明示せず、選好データから直接方策を最適化する手法。
- off-policy 的な比較対象として使われる。
- 論文では、Open-Instruct を用いて実装し、評価フレームワークとしてolmes.2 を用いる
- olmes.2:
- 正式には OLMES = Open Language Model Evaluation System で、Allen Institute for AI が公開している、LLM を再現可能に評価するための仕組み
PRIME
- Process Reinforcement through Implicit Rewards
- 本論文で重要な実験対象で、72%未更新、8%相殺、20%一貫更新という分析に使われる
ORPO / KTO / SimPO
- DPO系の選好最適化アルゴリズム。
- いずれも更新スパース性の検証対象。
Learning from In-distribution
- 現在のモデルの方策分布に近い分布から得られたデータで学習すること
- 本論文では更新スパース性の主要因とされる。
| RLのデータサンプリング方法 | そのデータが現在の方策に近いか | 理由 |
|---|---|---|
| on-policy RL | 基本的に in-distribution になりやすい | 学習中の現在の方策 πθ\pi_\thetaπθ からサンプルを生成して学習するので、基本的には in-distribution になりやすい |
| off-policy RL | in-distribution の場合も out-of-distribution の場合もある | 固定された外部データ、過去のモデルの生成、別モデルの出力、人間データなどを使うので、必ずしも in-distribution ではない |
- たとえばDPOのような off-policy は、RLの前に同じデータでSFTしておくと、モデルはそのデータ分布にすでに適応している。するとDPO時点では、データは現在の方策に近くなり、off-policyだがin-distributionに近いRLになる
- 逆に、SFT なしでいきなり現在の方策から遠い選好データに対してDPOを行うと、off-policyかつout-of-distributionになりやすく、その場合は論文では密な更新が起きたと報告されている
On-policy RL
- 学習中の現在の方策 からサンプルを生成して学習する RL。PPO、GRPO、PRIME など。
- in-distribution 学習になりやすい。
Off-policy RL
- 固定された外部データ、過去のモデルの生成、別モデルの出力、人間データなどを使うので、必ずしもin-distributionになるとは限らない。
- ただし、そのデータが現在の方策分布に十分近ければ、off-policyでもin-distribution 的に振る舞うことがある
- DPOやKTOの文脈で出てくる。
RFT / RAFT++
- リジェクションサンプリングを用いた微調整(Rejection-sampling fine-tuning)
- ベースモデル、または現在のモデルに複数回答を生成させる
- 正解判定器、報酬モデル、ルールなどで良い回答だけを残す
- 残した回答を教師データとしてSFTする
- RAFT++ は反復的な RFT
Rejection sampling
- 生成候補の中から良いサンプルを選んで学習に使う手法。
- in-distribution な SFT/RFT の要素として重要。
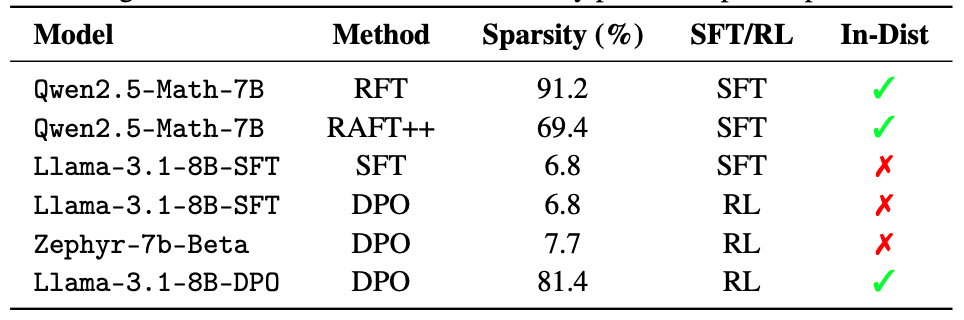
- in-distribution データでの SFT でもスパース更新が起きることを示す対照実験としてリジェクションサンプリング微調整を実施。
- out-of-distribution データで学習する→密な更新になる可能性が示された
- Qwen/Qwen2.5-Math-7B に対してリジェクションサンプリングされた in-distribution データで SFT を行うと約 90.0% の更新スパース性が得られた
- 現在の方策分布から離れたデータ。
- SFTや一部DPOで密な更新を生みやすい。
Out-of-distribution data
KL-divergence regularization(KL正則化)
- 方策が参照モデルから離れすぎないための正則化。方策の変化を制約する
- 本論文では、直観に反して、KL正則化の更新スパース性への影響は限定的とされる。
Reference policy / Reference model(参照モデル)
- KL 正則化で比較対象となる基準モデル。
- 通常は事前学習済みモデルやSFTモデルを採用する。
Gradient clipping
- 勾配や更新量を制限して学習を安定化する手法。
- こちらもKL正則化と同様に、直観に反して、スパース性の主因ではないとされる。
Update sparsity
- 微調整前後で変化しなかったパラメータの割合
- DeepSeek v3 base:8Kステップを超える大規模学習を行っているにもかかわらず、86.0% の更新スパース性
- 同一モデルファミリー内では、より大きなモデルほど高いスパース性を示す傾向が観察された
- 更新スパース性が自然に生じることを示唆している
- これらのモデルがいずれもスパース性を促す正則化手法や制約を用いず、フル微調整によって学習されているため
- 論文では bfloat16 の数値精度も考慮して測定
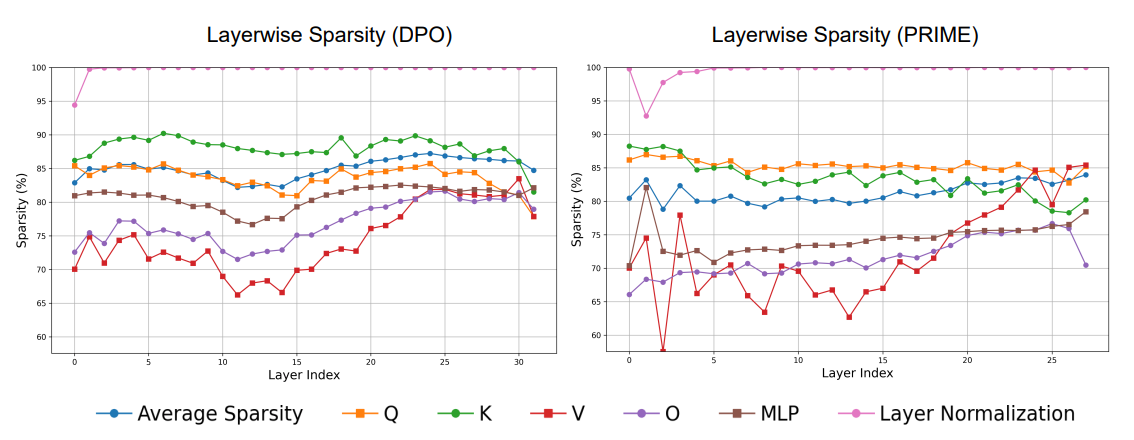
- RL におけるパラメータ更新が、モデルの各層や個々のパラメータ行列(例:Q、K、V 射影)にどのように分布しているか
- LayerNorm層だけは例外的にほとんど、あるいはまったく更新されない
- 比較的には、V, O, MLPが更新されやすい
- Transformer内の正規化層。バッチサイズに依存せず、サンプルごとに特徴量(チャネル)方向で正規化を行う
- 本論文ではほとんど更新されない例外的なコンポーネントとして重要。
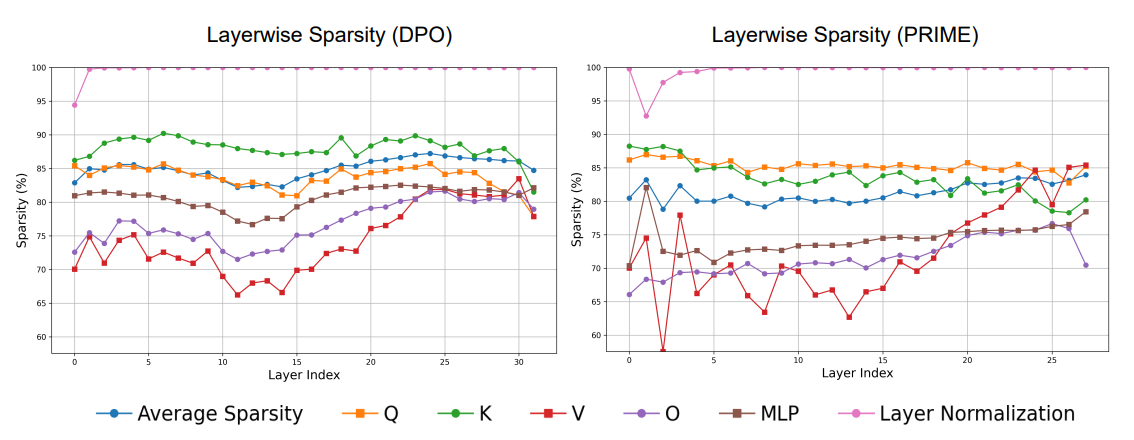
LayerNorm(Layer Normalization)
Subnetwork overlap
- 異なるシード、データ、アルゴリズムで得られたサブネットワーク同士の重なり。
- サブネットワークが偶然ではなく、再利用可能な構造かを見るための指標
- 片側重なり(片方のサブネットワークを基準にして、もう片方がどれだけその中身をカバーしているか)
- で更新されたパラメータのうち、にも含まれているものの割合
- で更新されたパラメータのうち、にも含まれているものの割合
- および :同じベースモデルから出発して、異なる条件でRL微調整したときにそれぞれ更新されたパラメータのインデックス集合
- :共通するサブネットワークの大きさ
- および :モデルのスパース性
- および :観測された重なり
たとえば、
- が 100個の更新パラメータを持つ
- と共通するものが60個ある
なら、
つまり 「の 60% が にも含まれている」 という意味。
- 観測された重なり
- 初期化が変わっても、得られるサブネットワークはランダムベースラインを大きく上回る、かなりの重なりを示す
- ランダムに同じ数のパラメータを選んだ場合との比較基準。
- サブネットワーク重なりの有意性を見るために用意されたベースライン。
- 「A が B にどれだけ含まれるか」と「B が A にどれだけ含まれるか」は別物
- 「片側」と呼ぶのは、分母を にするか にするかで値が変わるから。たとえば のサイズが大きい場合、 は高くても、逆向きの は低くなることがある
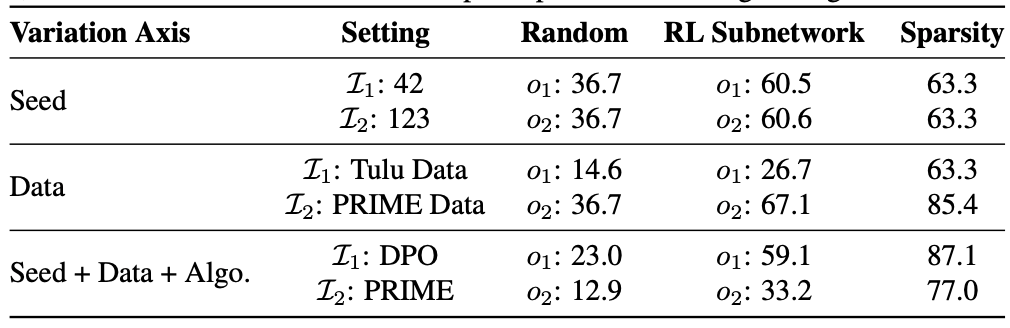
Random guessing baseline
Overview
WHAT(これは何?)
- 大規模言語モデルに対する強化学習ベースの微調整において、全パラメータを更新可能にしているにもかかわらず、実際には全体の約 5〜30%程度から成るスパースなサブネットワークのみが実質的に更新される、という現象を実証的に示した研究
- 著者らはこの現象を RLによって誘発されるパラメータ更新スパース性 と位置づけ、PPO、GRPO、DPO、PRIMEなど複数のRLアルゴリズムおよび複数のLLMファミリーを観測している
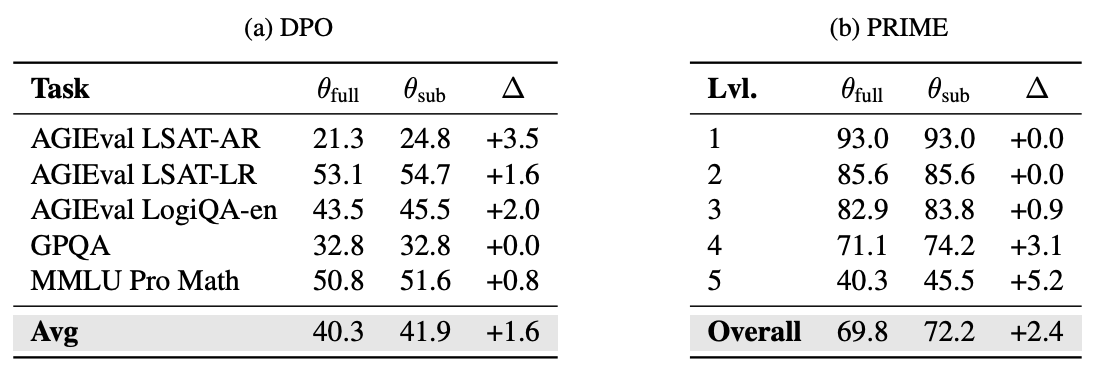
- さらに、更新されたサブネットワークのみを微調整しても、フル微調整モデルと同等の性能およびほぼ同一のパラメータ値が再現されることを示している
- DPOおよびPRIMEで学習した と のテストセット性能。サブネットワークのみを学習した は、フル微調整した よりも高い性能を達成し得る。Lvl. はMATH500の難易度レベルを示す。
WHY(提案手法の価値は?)
- 本研究の価値はLLMのRL微調整における「どのパラメータが実際に学習に寄与しているのか」という問題に対し、経験的かつ定量的な証拠を与えた点にある
- 従来、RLによるポストトレーニングでは全パラメータを更新することが一般的であったが、本研究は、実際には大部分のパラメータが不活性なままであり、少数の一貫したサブネットワークが主要な役割を担っている可能性を示した
- これにより、RL微調整の計算効率化、パラメータ凍結戦略、サブネットワーク再利用、より効率的な RL学習手法の設計に向けた実証的基盤を提供している
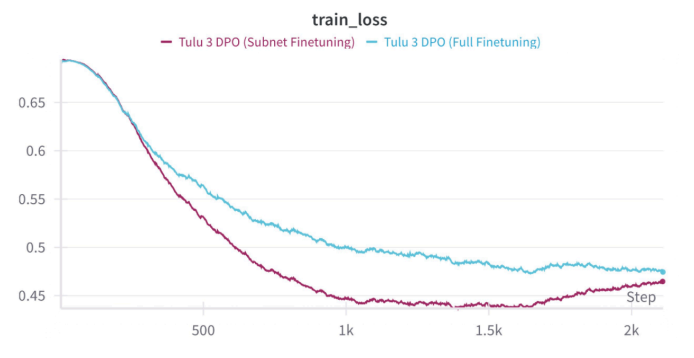
- サブネットワーク微調整とフル微調整でDPOを学習した際の訓練損失。サブネットワークを単独で学習した場合、訓練損失は一貫して低くなる
- 学習中に更新しないよう固定されたパラメータ。
- サブネットワーク外のパラメータを凍結しても性能が保たれる点が重要。
Frozen parameters
WHERE(技術のキモはどこ?)
- 本研究の核心は、RL微調整における更新が単に「少数の層」や「低ランク部分空間」に集中しているのではなく、ほぼすべてのパラメータ行列にわたってスパースに分布しつつ、その更新行列は多くの場合ほぼフルランクである、という点にある
- RL微調整後の各モデルにおける更新行列の平均ランク。最大可能ランクに対する割合 → ほぼフルランク

- すなわち、RL は少数のパラメータしか更新しない一方で、その更新はLoRAのような低ランク制約とは異なり、各行列が表現し得る空間の広い範囲に影響を及ぼし得る
- 低ランク部分空間に更新を制約する、効率的なパラメータ微調整手法。
- 本論文のスパース更新は、LoRAのような低ランク更新とは異なり、スパースだがフルランクに近い
LoRA
- また、このスパース性の主因として、方策分布に近いin-distributionデータで学習していることが示唆され、KL正則化や勾配クリッピングの影響は限定的であると分析されている